进制转换专题
使用sscanf将字符数组转为整型的办法
1 |
|
字符串到整数
1 |
|
整数到字符串(十进制转字符串)
1 |
|
十进制转其他进制
1 |
|
其他进制转十进制,strtol最容易搞忘
1 |
|
任意进制函数转换
1 |
|
strtol和itoa配合使用转换实例
1 | /*给出两个不大于65535的非负整数,判断其中一个的16位二进制表示形式,是否能由另一个的16位二进制表示形式经过循环左移若干位而得到。 循环左移和普通左移的区别在于:最左边的那一位经过循环左移一位后就会被移到最右边去。比如: 1011 0000 0000 0001 经过循环左移一位后,变成 0110 0000 0000 0011, 若是循环左移2位,则变成 1100 0000 0000 0110*/ |
strtol函数用法
1 | long int strtol(const char *str, char **endptr, int base) |
手工完成其他进制转十进制,十进制转其他进制
1 |
|
大数进制转换,大数除法
1 |
|
另一种更为简单的描述,大数转换两次
1 |
|
容器函数使用专题
string.h库函数memset()置零
1 | char *strcpy(char *dest, const char *src) |
reverse()逆置函数algorithm头文件
1 |
|
strrev逆置字符数组
1 |
|
排序sort函数
1 |
|
stable_sort()稳定排序
1 | //学生成绩排序 |
algorithm头文件next_permulation函数(全排列)
1 | // next_permutation example |
vector容器insert函数
1 |
|
vector容器pop_back(),erase()方法删除元素
1 | ---- 向量容器vector的成员函数pop_back()可以删除最后一个元素. |
string容器实用函数
1 |
|
string::substr方法总结
1 | // string::substr |
erase删除方法总结
1 | string str = "hello c++! +++"; |
find方法总结
1 | string (1) |
find和erase联合使用实例
1 |
|
replace使用方法
1 | 用法一:用str替换指定字符串从起始位置pos开始长度为len的字符 |
string函数应用实例,小数指数转换
1 | 4 00.00120 000.012345 |
reverse()函数使用方法
1 |
|
swap函数使用
1 | C++中的swap函数:交换函数 |
set容器使用
1 | #include <set> |
map容器使用
1 |
|
map使用实例,借用key的自动排序功能:
1 |
|
unorder_map容器使用(hash树)
1 |
|
堆栈+ordermap使用括号匹配
1 |
|
堆栈使用简单计算器
1 |
|
栈+队列实现中缀转后缀,计算后缀表达式
1 |
|
栈+队列计算,包括括号版
1 | 48*((70-65)-43)+8*1 |
另一种直接写法,不会栈溢出
1 |
|
队列使用
1 |
|
任务调度:优先队列+string处理和unordermap
1 | //优先队列进行任务调度 |
输入输出专题
控制小数点后精度位数及补齐整数位数
1 |
|
scanf输入规则
1 | //输入字符 |
其他输入规则,getchar(),cin,get(),gets()如何终止循环输入跳出
1 | string str; |
sstream输入流
1 |
|
sstream输入排序实例istringstream
1 | /* |
sscanf输入实例
1 |
|
文件操作
1 |
|
strlen和sizeof区别
1 | //c语言没有字符串,用的是字符串数组来模拟字符串,c风格字符串数组再末尾加0表示结尾 |
short ,int,long区别
1 | 1、16位编译器 |
transform函数应用大小写转换
1 | unary operation(1) |
链表专题
链表增删改查
1 |
|
链表选择排序法+找到新节点排序位置再插入
1 |
|
单循环链表+合并
1 |
|
链表查找和交换
1 |
|
链表如何删除最大值,排序,释放结点
1 |
|
循环链表删除结点
1 |
|
链表中的排序操作,链表复制s[k]用法
1 | 1 78 90 56 |
静态链表实现链表部分反转
1 | //输入形式 |
树专题
静态创建新结点、构造二叉树实现前序中序遍历还原
1 |
|
二叉排序树查找、插入、构造科学方法
1 | 7 |
二叉排序树建立,非递归遍历方法
1 | /*第三题:输入一个字符串,建立一个二叉排序树,并中序遍历输出;*/ |
无冗余字符串数组加建立二叉排序树
1 |
|
如何创建树链表,进行逆中序遍历
1 | /*输入一个数列以0结尾,建立二叉遍历数,并对其进行逆中序遍历,释放空间*/ |
后序加中序还原加层序遍历
1 | 7 |
排序算法-冒泡、选择
1 | //冒泡排序,每次都将一个最大的浮出水面 |
高低字节交换,循环左右移动
1 | //十六进制的表达0xff前面是填充4字节 |
移位二进制表达
1 |
|
16位循环移位
1 | //做复杂了!!位操作就可以解决,结合进制转换一起学习 |
函数指针数组
1 |
|
如何定义二维数组并初始化new方法使用
1 | int M = 10, N = 5;//10行5列。 |
动态分配内存,new方法
1 |
|
动态分配内存,实现输入无限制长度字符串malloc和realloc
1 |
|
无冗余输入字符串
1 |
|
char和string的转换方法
1 | char c[20]; |
日期问题
日期问题的常规操作
1 | /*给出年份m和一年中的第几天,算出第几天是几月几号,按照yyyy-mm-dd格式打印*/ |
日期问题相差天数
1 | //太复杂的做法 |
利用日期差值求星期
1 |
|
矩阵转置
1 |
|
for循环的进阶用法
1 |
|
结构体查找学生信息新办法
1 |
|
图形题漏斗,两种思路
1 |
|
1 | d |
打印图形,上下翻转
1 | C |
哈希专题
hash表的用法
1 |
|
hash表高阶用法,二维数组存放不同组的hash值
1 |
|
hash结合字母表处理字符串的使用方法
1 | //这个题的输出处理方式太强了 |
递归专题
递归加上图形按规律打印
1 | /* |
另一种方向的递归
1 |
|
循环递归+全排列
1 |
|
求组合数递归
1 |
|
递归组合+判断素数,一加一减显示递归的路径
1 |
|
八皇后遍历全排列版+剪枝版
1 |
|
走迷宫-深度遍历DFS版
1 | //深度优先遍历解决迷宫问题 |
计算矩阵中含1块-BFS版
1 | 6 7 |
BFS得出玛雅人密码交换次数
1 | /* |
广度优先-迷宫
1 | 5 5 |
走巨石掉落迷宫,高级版
1 |
|
求方程解,多重循环处理
1 | //著名的八皇后问题 |
矩阵乘法
1 | //大佬的输入处理和轻描淡写的循环 |
分数矩阵乘法,简单版和复杂版
1 | /* |
贪心算法,求代理服务器访问IP方法
1 | /* |
大数专题
字符加减关系,实现任意长度整数相加
1 |
|
大数加法,进阶转换版
1 |
|
大数浮点数加法
1 |
|
大数运算之阶乘
1 | /* |
图专题
并查集,寻找父节点,合并模板
1 | /* |
图的遍历DFS邻接矩阵和邻接表法
1 | //给定一个无向图和所有边,判断这个图是否所有顶点都是联通的 |
迪杰特斯拉求最短路径长度+从某点到另一点的路径
1 | 6 8 0 |
优先队列实现地杰斯特拉
1 |
|
prim最小生成树算法
1 |
|
并查集+最小生成树
1 |
|
克鲁斯卡尔最小生成树
1 | 6 10 |
动态规划专题
最大连续子序列求和
1 | //最大连续子序列和,最简单基础班 |
方法二:很巧妙
1 |
|
最大加权子矩阵-矩阵压缩
1 | //最大加权矩形变形,只需要矩阵的和大于k来求矩阵的面积!! |
最长不下降子序列
1 | //最长不下降子序列,此处不要求连续,只要求是递增,间隔也可,因而双循环 |
最长不下降子序列应用
1 | /*N位同学站成一排,音乐老师要请其中的(N-K)位同学出列,使得剩下的K位同学不交换位置就能排成合唱队形。 合唱队形是指这样的一种队形:设K位同学从左到右依次编号为1, 2, …, K,他们的身高分别为T1, T2, …, TK, 则他们的身高满足T1 < T2 < … < Ti , Ti > Ti+1 > … > TK (1 <= i <= K)。*/ |
最长公共子序列-字符串A,B
1 | sadstory |
最长公共子序列求具体LCS
1 | /* |
hash字符串求最长公共连续子串
1 | /* |
最长公共子串是最长公共子序列的的特殊情况
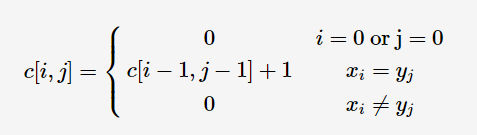
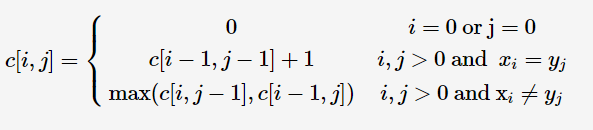
1 | public static int lcs(String str1, String str2) { |
最长回文子序列
方法一:递归方法,自顶向下
str[0…n-1]是给定的字符串序列,长度为n,假设lps(0,n-1)表示序列str[0…n-1]的最长回文子序列的长度。
1.如果str的最后一个元素和第一个元素是相同的,则有:lps(0,n-1)=lps(1,n-2)+2;例如字符串序列“AABACACBA”,第一个元素和最后一个元素相同,其中lps(1,n-2)表示红色部分的最长回文子序列的长度;
2.如果str的最后一个元素和第一个元素是不相同的,则有:lps(0,n-1)=max(lps(1,n-1),lps(0,n-2));例如字符串序列“ABACACB”,其中lps(1,n-1)表示去掉第一元素的子序列,lps(0,n-2)表示去掉最后一个元素的子序列。
1 |
|
方法二:自底向上动态规划方法
1 |
|
最长回文子串,连续的!!
动态规划法:
回文字符串的子串也是回文,比如P[i,j](表示以i开始以j结束的子串)是回文字符串,那么P[i+1,j-1]也是回文字符串。这样最长回文子串就能分解成一系列子问题了。这样需要额外的空间O(N^2),算法复杂度也是O(N^2)。
首先定义状态方程和转移方程:
P[i,j]=false:表示子串[i,j]不是回文串。P[i,j]=true:表示子串[i,j]是回文串。
P[i,i]=true:当且仅当P[i+1,j-1] = true && (s[i]==s[j])
否则p[i,j] =false;
1 | PATZJUJZTACCBCC |
暴力法:
遍历字符串S的每一个子串,去判断这个子串是不是回文,是回文的话看看长度是不是比最大的长度maxlength大。遍历每一个子串的方法要O(n^2),判断每一个子串是不是回文的时间复杂度是O(n),所以暴利方法的总时间复杂度是O(n^3)。
1 | PATZJUJZTACCBCC |
中心扩展法:
中心扩展就是把给定的字符串的每一个字母当做中心,向两边扩展,这样来找最长的子回文串。算法复杂度为O(N^2)。
但是要考虑两种情况:
1、像aba,这样长度为奇数。
2、想abba,这样长度为偶数
1 |
|
判断是否为回文串:
1 |
|
实际应用,输出回文子串
1 | Confuciuss say:Madam,I'm Adam. |
01背包问题
1 | /* |
完全背包-拆分整数成2的幂的和
1 |
|
动态规划解决括号最长匹配长度
1 | /*方法一没怎么看懂,不过dp[i]应当表示以i号开头时最长长度*/ |
方法二:更容易理解,但是一用例居然没有通过
1 |
|
动态规划花钱类问题两种思路
动态规划自底向上方法
1 | /* |
递归方法,自顶向下:
1 | /* |
递归+动态规划解决组合数问题
1 | /* |
字符串专题
1.统计单词频率
1 |
|
1 |
|
2.密文加密
1 |
|
cctype头文件中处理字符函数

3.find使用,删除指定子串,transform使用
1 | 对于字符串string,需要使用string头文件,包含以下常用方法: |
4.字符串前缀识别
1 |
|
给定字符串找出重复字符和位置,*号法
1 | /*对于给定字符串,找出有重复的字符,并给出其位置*/ |
5.string循环截取的两种办法
1 | //记录当前位置截取法,有当前位置和新位置,不改变原来字符串 |
6.读入用户输入的,以“.”结尾的一行文字,统计一共有多少个单词
1 | 2、 |
7.找出数组中最长无重复子串的长度
1 | /* |
方法二:
1 |
|
8.手机键盘按键,find和hash办法
1 | /* |
好方法:
1 |
|
9.给定一个0字符串,求出全部子串出现次数
1 |
|
方法二:朴素手写方法
1 | //一前一后两个指针来截取子串 |
数学专题,模拟
素数问题,普通筛和埃氏筛
1 | bool judge(int x){ |
1 | //埃氏筛法 |
另一种筛法,连续素数求和得超级素数
1 | //超级素数要求是连续几个素数之和 |
质因数
1 | //埃氏筛法 |
1 | 方法二:太强了!!,这个逻辑 |
奇数魔方图
1 | //C程序设计第五版(谭浩强) |
求小数的循环部分,模除法
1 |
|
求最大公约数
1 | int gcd(int a,int b){ |
求最小公约数
求得A和B的最大公约数是C,则最小公倍数A*B/C
矩阵排序思想
1 | /*输入一个四行五列矩阵,找出每列对最大的两个数*/ |
求约数节省效率办法
1 |
|
简单约瑟夫环
1 | /*n个人排一圈123报数,报到3的人退到圈外,直到剩最后一个人为止。*/ |
高级链表版约瑟夫环(单循环链表)
1 |
|
约瑟夫环再进阶版,拆封成.h和.c多个文件
1 | /* |